







© IE Online Media Services Pvt Ltd
Tags:

Worried about your personal data being sent to China while accessing DeekSeek R1, the cutting-edge large language models (LLM) that has taken the Internet by storm? Well, there is a way to mitigate privacy-related issues while using it, and other LLMs––by running them locally on your device.
While there are many tools for Windows PCs that can natively run open-source AI models such as DeepSeek or Llama 3, in our testing, we found that LM Studio is one such free tool, and in our opinion, one of the best, available for PC, Mac, and Linux. Although you can run smaller models with fewer parameters on any device, it is best to run these models with a fairly powerful CPU, GPU, and a PC that has at least 16 GB of RAM.
With LM Studio, you can run cutting-edge language models like Llama 3.2, Mistral, Phi, Gemma, DeepSeek, and Qwen 2.5 locally on your PC for free. Do note that we recommend running smaller models with fewer than 10 billion parameters, commonly known as distilled models.
These models are compressed using a process called distillation––to condense all their knowledge into a smaller package––and are faster and more efficient versions of their larger counterparts. These models are optimised to ensure they deliver better results.
Depending on the AI model you choose, you might need around 10 GB of data and storage space on your PC, as the resources to run an LLM need to be downloaded to your computer. Once everything is downloaded, you can access the AI models even when you are offline.
Download and install LM Studio from lmstudio.ai.
Once installed, the tool prompts you to download and install the distilled (7 billion parameters) DeepSeek R1 model.
You can also download and use any of the other open-source AI models directly from LM Studio.
When you use an AI model locally on your PC via LM Studio for the very first time, you might have to load the model manually. Depending on the size of the model, it could take from a couple of seconds to a few minutes to fully load.
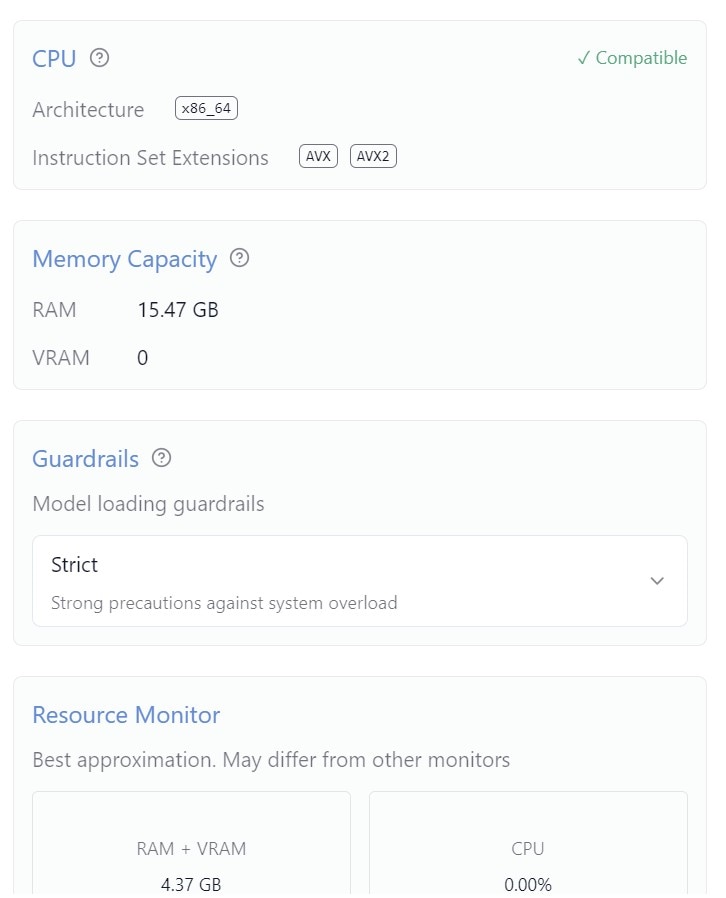
Depending on the computing capabilities of your PC, the response from an AI model running locally could take longer. On top of that, keep an eye on the system resource usage at the bottom right corner. If the model is consuming too much RAM and CPU, it’s best to switch to an online model.
Additionally, you can run an AI model in three modes: User, which offers minimal customisation support; Power User, which offers some customisation features; and Developer Mode, which enables additional customisation capabilities. If you have a laptop with an NVIDIA GPU, you could get better performance from the AI model.

The best way to check is by turning off the Wi-Fi and disconnecting the Ethernet on your PC. If the model continues to respond to your queries even when you are offline, it is an indicator that it is running locally on your PC.
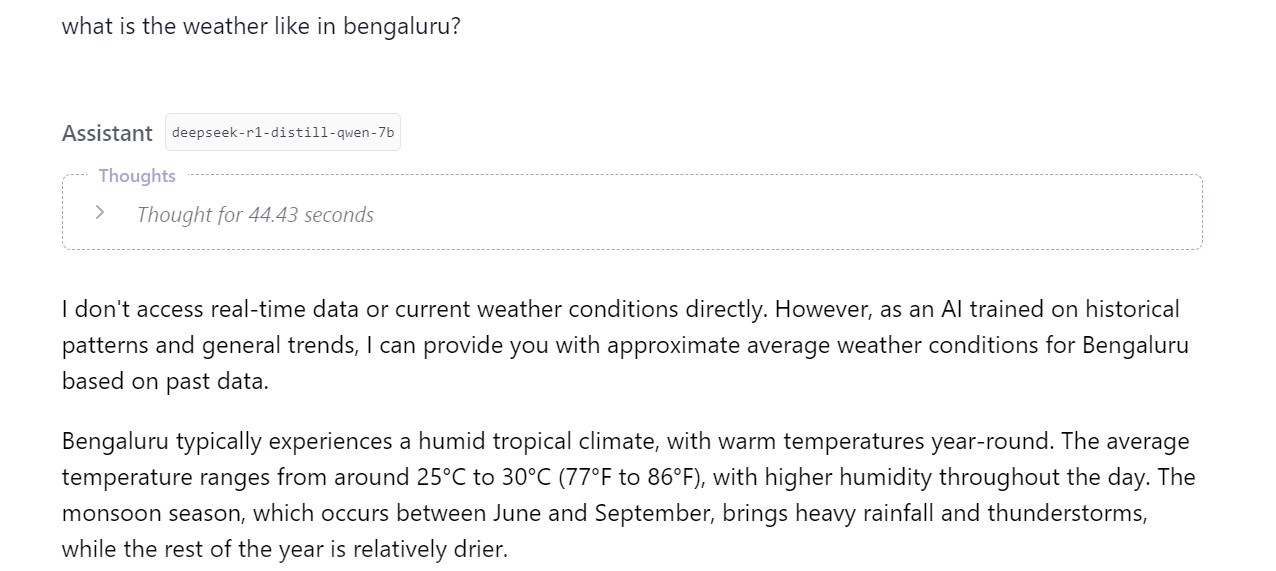
I ran the DeepSeek-R1-Distill-Qwen-7B-GGUF on a thin-and-light notebook with an Intel Core Ultra 7 256V chip and 16 GB of RAM. In my usage, I noticed that the model was fairly fast to respond to some queries, while it took as long as around 30 seconds for other responses. During active usage, the RAM usage was around 5 GB, and the CPU usage was around 35 per cent.
While this does not affect the actual quality of the response, depending on the query, you might have to wait longer for the AI model to generate the response.
For anyone concerned about data privacy, running a model locally is definitely a great solution, especially for those who don’t want to miss out on the latest innovations.

